Distributed DNAT with Netfilter: misusing states
introduction
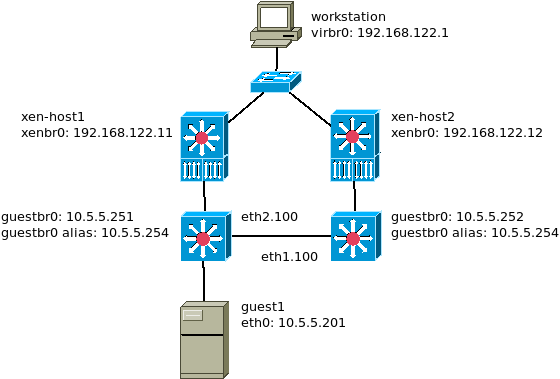
This is a network-convergent XEN cluster using stateless NAT:
one gateway per node with public ip — fully convergent outbound flows for guests, as seen in part1 and part2,
and since we are assuming DNS round-robin or load-balancing from a CDN provider, partially convergent inbound flows for guests. A connection request comes on one node, while the answer goes to another node, this is what we are discussing here.
note we’re using kvm for this poc hence the 192.168.122.0/24 subnet instead of public addresses.
description
That one was a long run.
Not only we’ve hacked around NAT states in a distributed fashion, but we also managed to avoid tagging frames and misusing DSCP on the peer nodes.
We simply add a meta tag on the cluster pipes, hence only when the frames are foreign.
The Netfilter netdev family doesn’t allow to set a CT mark right away.
Therefore, on the way to the guest, we set a CT mark based on the meta mark, so the returning packet will still have it
(that wouldn’t occur with a DSCP tag nor with the defined meta tag, as those are only relevant to packets and do not handle flows).
However, the link between the other nodes and the guest is just L2 bridging, no CT happens there by default
— we had to load the br_netfilter module for L3 filtering to take place, and enable CT for those foreign and unknown frames on the fly.
why such a mess?
Yes, the rule of thumb for every engineer is KISS, right? I admit the setup is more complicated than for a casual infrastructure with dedicated network devices (be it appliances or bare-metal). However let us have a look at layer 1 diagrams. Here’s what a usual NAT setup would look like including redundancy and eventually synchronized states.
┌───────────┐ ┌───────────┐
│ │ │ │
│ lbs1 │ │ lbs2 │
│ │ (pfsync) │ │
└───────────┘ └───────────┘
┌──────────────────┐ ┌──────────────────┐ ┌──────────────────┐
│ │ │ │ │ │
│ node1 │ │ node2 │ │ node3 │
│ │ │ │ │ │
└──────────────────┘ └──────────────────┘ └──────────────────┘
In case we take into account network appliances or virtual network devices such as commonly used OPNsense, there are still unnecessary guests in place:
┌──────────────────┐ ┌──────────────────┐ ┌──────────────────┐ │ │ │ │ │ │ │ node1 │ │ node2 │ │ node3 │ │ ┌────────┐ │ │ │ │ ┌─────────┐ │ │ │ lbs1 │ │ │ │ │ │ lbs2 │ │ │ └────────┘ │ │ │ │ └─────────┘ │ └──────────────────┘ └──────────────────┘ └──────────────────┘
And here’s what our infrastructure looks like.
┌──────────────────┐ ┌──────────────────┐ ┌──────────────────┐ │ │ │ │ │ │ │ node1 │ │ node2 │ │ node3 │ │ │ │ │ │ │ └──────────────────┘ └──────────────────┘ └──────────────────┘
Which architecture looks overly complicated now? The first achieved goal is hardware resource convergence and cost reduction — and for the least, no required guest compared to network appliances.
The second goal is network performance improvements under heavy load and particularly when the cluster farm grows horizontally. On a traditional setup, the datagrams go back and forth between the servers and network devices. Here is a functional view of an inbound flow arriving on lbs2.
│ ▲
│ │
│ │
│ │
│ │
│ │
┌──────────────────┐ ┌──────────────────┐ ┌─────────▼────┼───┐
│ │ │ │ │ │ │
│ node1 │ │ node2 │ │ node3 │
│ ┌────────┐ │ │ ┌────────┐ │ │ ┌─────────┐ │
│ │ lbs1 │ │ │ │ guest │ │ │ │ lbs2 │ │
│ └────────┘ │ │ └──┬─────┘ │ │ └───┬─────┘ │
└──────────────────┘ └──────────┼────▲──┘ └──────────┼──▲────┘
│ │ │ │
│ └────────────────────┘ │
└────────────────────────────┘
And here is what the inbound flow looks like in our setup.
▲ │
│ │
│ │
│ │
│ │
│ │
│ │
│ ▼
┌──────────────────┐ ┌──────┴───────────┐ ┌──────────────────┐
│ │ │ │ │ │
│ node1 │ │ node2 │ │ node3 │
│ │ │ ┌────────┐ │ │ │
│ │ │ │ guest │ │◄─────┤ │
│ │ │ └────────┘ │ │ │
└──────────────────┘ └──────────────────┘ └──────────────────┘
As this is usually not a problem with dedicated bare-metal and large enough pipes, our use-case especially makes sense compared to virtual appliances, as the traffic would otherwise go back and forth between the host nodes, which are already busy handling various kinds of traffic namely guest systems, storage and what-not. Those nodes, which are hosting the load-balancers (and eventually outbound gateways), may become overloaded by managing the network traffic of all the cluster, while we spread the load across all nodes in our setup (for inbound flow answers and outbound flows).
On a server infrastructure, the vast majority of the network traffic is inbound initiated, meaning the flow begins while receiving a client request. We assume DNS round-robin against a few nodes (not necessarily all of them, but we will address this in part 5 or part 6). Some packets may end-up on the right cluster node, some packets may not and would be sent to some other node. That means the inbound traffic is partly indirect. The answer we are sending to the client, however, goes directly through the host system. Performance improvement should therefore be half-proportional to the number of cluster nodes minus 1.
Outbound initiated flows happen more rarely for server farms, however this is where we got most impressive performance gains, as both directions of the flow become direct. The outbound setup might be particularly worth considering in case of VDI farms (virtualized desktop systems), botnets and such, anything basically, where client-side activity is prominent. Performance improvement should be absolutely proportional to the number of nodes minus 1.
Not really a third goal, but a side effect: one might consider that in case of heavy load, nodes do not have to track the states of the whole cluster (which synchronized states do), while keeping the benefits of synchronized states (for exemple, assuring an SSH or Websocket session while live-migrating the guest hosting it, across virtualization nodes).
architecture
The achitecture is the same as in part3 but testing with only one guest, living on node1. Also we absolutely need to keep the source IP as-is (no full-nat here), otherwise the returning node wouldn’t know where to send the answer.
setup
This PoC leverages only two nodes but the cluster can scale at will, thanks to the per-node tags (MAC address <> CT mark conversion).
vi /etc/rc.local # node1 ifconfig guestbr0 hw ether 0a:00:00:00:01:00 # node2 #ifconfig guestbr0 hw ether 0e:00:00:00:01:00 echo -n restart nftables ... systemctl restart nftables && echo OK || echo NOK echo -n load br_netfilter... modprobe br_netfilter && echo OK || echo NOK # node1 only echo start xen guest guest1 xl create /data/guests/guest1/guest1 vi /etc/sysctl.conf net.ipv4.ip_forward = 1 net.ipv4.conf.default.arp_filter = 1
now that one is managed by Ansible
#vi /etc/nftables.conf vi templates/nftables.martinez.conf.j2
same setup on all nodes - add/update the MAC addresses accordingly
see https://ansible.nethence.com/network/nftables/templates/nftables.martinez.conf.j2
acceptance
from workstation
check distributed DNAT works (this test matters more)
curl -i 192.168.122.12
==> foreign state OK
check there’s no regression on local DNAT
curl -i 192.168.122.11
==> local state OK
check outbound stateful SNAT esp. its implicit DNAT still works
from guest1 within node1
ssh bookworm1 xl console guest1 ping -c2 192.168.122.1 ping -c2 opendns.com
==> ICMP reply from workstation and public network reaches back down to the guest
discussion
mainteance
This is a low-level cluster node setup and no live changes are expected to be done on the network filters. Guest systems will do their firewalls if they want. We are just natting. There’s however a technical choice to make regarding maintenance costs:
KISS and hard-code MAC addresses to tag frames on the cluster pipes with
netdev, like I did heretag frames right away no matter what, when those enter a node
I prefer the former as it reduces mangling overhead. We just need to update nftables.conf when adding a cluster member.
d-un-nat vs. snat
There’s a bit of a situation with stateful SNAT handling which conflicts with our stateless D-UN-NAT. I solved it by re-introducing tags even though frames are local (and disabling the catch-all-at-last dunnat rule), and carefully giving a lower priority to dunnat-spoof compared to stateful snat.
Strangely enough, the priority -150 for diy-dnat was not enough, I had to use -300 even though this is a meta tag, not a CT tag.
resources
https://wiki.nftables.org/wiki-nftables/index.php/Netfilter_hooks
Licensed as MIT